As a data management & architecture consultant, my goal is to help businesses create the bedrock for data science and analytics. That said, I seldom miss a chance to take a stab at the analytics problems that come my way. This penchant for being intrigued by interesting ideas and problems, especially those involving data & technology, reminded me of the story where one of Richard Feynman's long term friends and collaborators, Danny Hills, says that for Feynman, working on "a crazy idea was an opportunity to either prove it wrong or prove it right. Either way, he was interested." Although I'm nowhere close to Feynman in terms of genius, my approach to working on interesting problems is similar, albeit at a much lower level of complexity and scale.
Problem #1: Variables or Variable-Groups?
Most of my friends know that I'm interested in problems involving data. So my cousin recently brought me a problem he was facing at work with a time series forecasting model that they were using to measure a product's usage during COVID. He did check whether I had experience with such problems, which again took me back to the above article where Hills says that "every great man he has known has had a certain time and place in their life that they use as a reference point; a time when things worked as they were supposed to and great things were accomplished. For Richard, that time was at Los Alamos during the Manhattan Project." Again, discounting the greatness part, for me, academically, such a reference-spacetime is at NUS, during my Master's course. Hills goes on to say that Feynman would often look back at that time, usually to understand the problem at hand better and apply the "best practices" from then, which is something I've also done at times, and since I had worked on time-series models at NUS, I readily agreed to help my cousin out.
In their model, they were using confirmed cases as an external factor and had to make the prediction for country, product-type, and any combination of these variables. For the prediction itself, they were using a model based on BSTS (Bayesian Structured Time Series), which was predicting accurately for one country and one dimension but they weren't sure how to make it work for multiple dimensions and countries (say 3 and 20 respectively), and they obviously didn't want to run the model so many times. So they were on the quest for a multi-variate model or a way to convert their model to be one. But after thinking about the problem and looking at it from different angles, I realised that they didn't need a multi-variate model but their model needed to have grouping by the columns. They were using Python (and pandas), so I suggested the method for "Grouping of multiple columns" described here.
Problem #2: Low R2 in regression
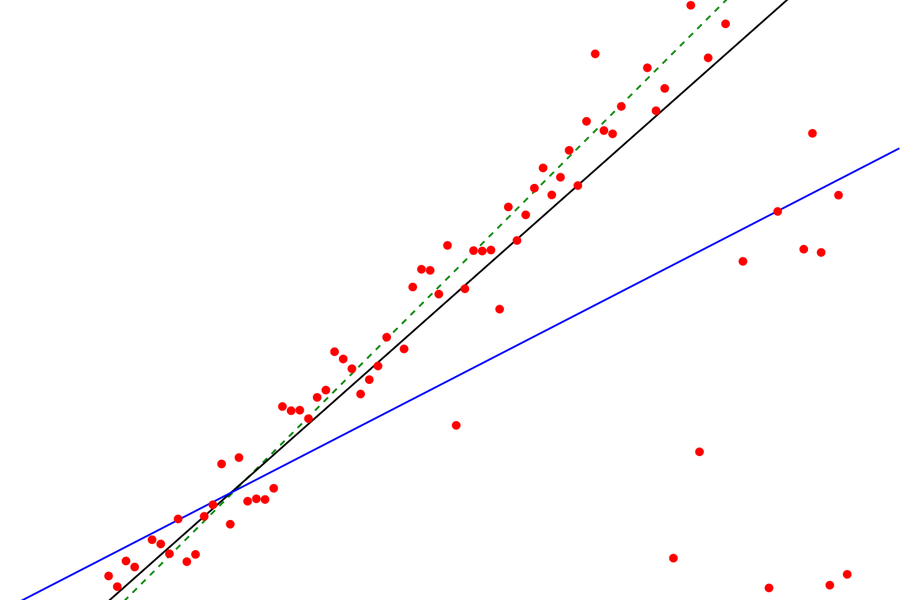
Another such data analysis problem came in the form of a request from an ex-colleague in a WhatsApp group. He had a dataset of critical process parameters of a manufacturing operation with 15 independent variables and one dependent variable. He'd tried a number of regression models (in Python/scikit-learn) with various combinations of parameters but did not get a good R2 (R-squared). He was seeing R-squared of 0.3 or lower, for a sample size 150.
Explicit vs. Tacit Knowledge
In my case here, there are two different but associated lessons from my reference-spacetime that can be applied now. One, of course, is to understand how regression works, what are R2 and adjusted R2 etc., and how they can be applied here. The other lesson, arguably the more important one, is the ability to elicit adequate and relevant information to assess the problem and while considering a solution, realising simple but important things like this is not Machine Learning (ML), this is regression, a statistical method, which is a precursor to ML. Although advances in statistical learning (a branch of ML derived from statistics) can be applied to some such problems, it's important to realise that ML is not the solution for all data problems. I would call the latter "meta" learning. In technical terms, borrowing from the field of Knowledge Management, the first type of knowledge is "explicit knowledge" and the second type is "tacit knowledge".
ML is not the solution for all data problems
Coming back to our regression problem, R2/R-squared is known as the coefficient of determination and is the proportion of the variance in the dependent variable that is predictable from the independent variable(s). So, typically, a low R2 indicates that though the independent variables might be significant, they are not useful in predicting the dependent variable. If we were running a regression based unsupervised ML model (unsupervised == no dependent variable) and had a (much) larger dataset (statistical learning), I might have suggested "principal component analysis", which modifies the variables based on the eigenvalues of eigenvectors created from them, to form "principal components" that work as better predictors.
To solve the problem, while remaining within our constraints (particularly the sample size), we use a concept called adjusted R2 (a.k.a A-R2 or R bar squared). Adjusted R2 is an attempt to account for the phenomenon of the R2 automatically increasing when extra explanatory variables are added to the model. So this is a modification of R2 that adjusts for the number of explanatory terms in a model relative to the number of data points.
It's derived from R2 thus:

Solution #2
Using A-R2, our technique is to start with 2/3 variables and add the others one-by-one (this works only for linear models) and measuring adjusted R-squared after each addition. At every iteration, if the A-R2 increased, it would mean that the variable is influential in making the prediction, so we’d keep the variable and if it decreased, we’d remove the variable. My friend also said that he noticed that the model could not predict the extremes well, so he decided to re-do the analysis.
On the whole, it was a satisfying experience to suggest a solution that worked and to rejig the memory and convert some "tacit knowledge" to "explicit knowledge". For implementation, advances in Python and libraries like scikit-learn have made the coding of such problems fairly straightforward but I wouldn't be surprised if a solution like this comes up for this where even the code is generated for you based on your requirements.
That's all, folks! So I can simplify the world of data for you. Please reach me at db@databeetle.net to schedule an initial consultation.
More such content...
Data Pipeline for Customer Success Dashboards

When less is more but bigger is better